Langchain. RAG общие принципы
Современные технологии обработки текстов, такие как ChatGPT и Langchain, открывают новые возможности для анализа данных. В этой статье мы рассмотрим основные принципы построения Retrieval-Augmented Generation (RAG) с использованием Langchain и связанных технологий, таких как Embedding и векторные базы данных.
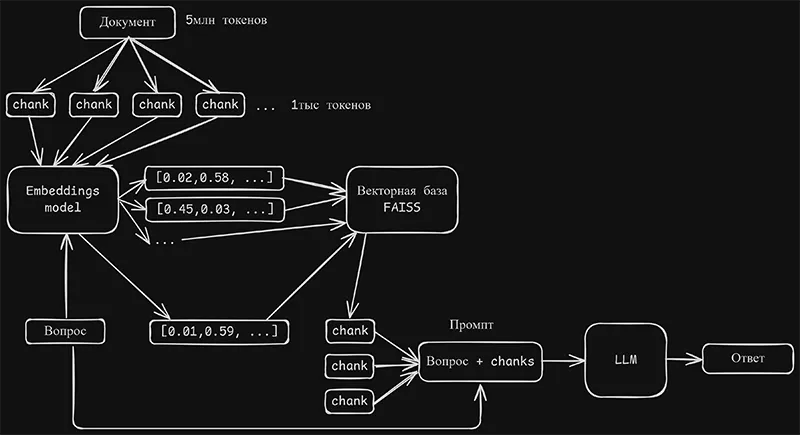
Основные концепции RAG
RAG — это метод, который позволяет улучшить работу языковых моделей, таких как ChatGPT, путем добавления внешних данных. Основная идея заключается в использовании базы данных, содержащей документы, для извлечения релевантной информации, которая поможет модели генерировать более точные ответы.
Разбиение документов на чанки
Большие документы разбиваются на более мелкие части — чанки. Обычно это делается на уровне тысяч токенов. Это необходимо, чтобы языковая модель могла обрабатывать данные эффективно и без потери качества. В Langchain существуют автоматизированные функции для разбиения текстов.
Использование Embedding и векторных баз данных
Embedding преобразует текстовые данные в векторные представления. Эти векторы затем хранятся в векторных базах данных, таких как FAISS. Преимущества использования векторных баз включают высокую скорость и объемы обработки данных. В нашем примере мы используем локальные модели Embedding из Hugging Face для преобразования текстов.
Поиск и извлечение релевантных данных
Когда пользователь задает вопрос, он также преобразуется в вектор. С помощью векторной базы данных, такой как FAISS, происходит поиск схожих векторов. Найденные чанки данных объединяются в промпт, который отправляется в языковую модель для генерации окончательного ответа.
Применение в корпоративной среде
RAG можно использовать для создания корпоративных чат-ботов, которые обрабатывают специфические запросы сотрудников. Например, информация о отпусках или должностных обязанностях может быть быстро предоставлена через бота, не отвлекая сотрудников от основной работы.
Заключение
Построение RAG с использованием ChatGPT и Langchain предоставляет мощные инструменты для обработки больших объемов текстовых данных. Эти технологии позволяют интегрировать внешние данные для улучшения качества ответов языковых моделей, что открывает новые возможности в различных сферах применения.
