Тестирование моделей ИИ: GigaChat 2 Max, Qwen 2.5 и Deepseek-r1
Приветствую всех, с вами Низамов Илья. Сейчас я активно работаю над созданием подсистемы тестирования для курса по llm проектам. Для примера я решил испытать разные модели при помощи промпта классификации запросов.
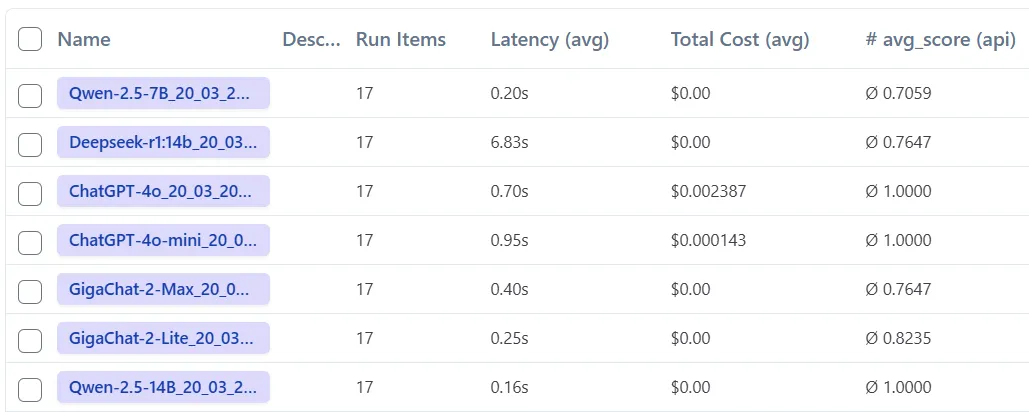
Начнем со Сбербанка, они запустил новую модель GigaChat 2 Max и активно ее пиарят. Однако, несмотря на все мои усилия, я не смог добиться от нее желаемого качества ответов в этой задаче. Я пробовал разные подходы, но результат оставлял желать лучшего. В отличие от GigaChat 2 Max, локальная модель Qwen 2.5 с 14 миллиардов параметров проявила себя на высоте. Она четко следовала инструкциям и показывала отличные результаты в тестах. Важно отметить, что Qwen 2.5 с 7 миллиардами параметров уже значительно уступала по качеству.
Не могу не упомянуть и Deepseek-r1 с 14 миллиардами параметров. В моем тесте классификации она не блеснула. Возможно, для нее требуется другой подход к написанию промптов, особенно если учитывается необходимость в размышлениях. К тому же, Deepseek-r1 работает медленно, что может быть дополнительным минусом.
Модели от OpenAI, как всегда, показали стабильные результаты. Однако, чтобы достичь нужного качества, пришлось приложить немало усилий. Новую модель ChatGPT 4.5 я пока не тестировал из-за ее высокой стоимости. Но, на проекте мы ее включали не надолго и эта модель показывает отличные результаты.
Таким образом, выбор модели зависит от ваших целей и бюджета. Если важна скорость и точность, Qwen 2.5 на 14b параметров - хороший вариант. Если бюджет ограничен, можно рассмотреть модели от OpenAI, хотя работа с ними требует больше времени и усилий. GigaChat 2 Max пока не оправдала ожиданий, но возможно, будущие обновления улучшат ситуацию.